GRPO: Building Intuition Through Ablation Studies
Following the same approach as I did for SFT and Expert Iteration, I have written the GRPO training code from scratch. I loosely followed GRPO experiment part of Stanford CS336 Assignment 5 as a reference point and trained Qwen2.5-Math-1.5B with verifiable math rewards. This time around I had 3 main motivations:
- As usual, write the GRPO code from scratch for the sake of understanding.
- Train Qwen2.5-Math-1.5B model with verifiable math rewards and get a feel of what kind of accuracy we can push with pure RL (no supervised fine-tuning).
- Most importantly, run a lot of ablation studies to understand and build intuition on what matters in GRPO training, the different design choices we can make and how to interpret the different metrics. Now I look back, I think this is the most important part of this long exercise.

Best: ~75% reward accuracy on MATH validation (up from ~3% base model accuracy)
Quick Recap on GRPO
GRPO (Group Relative Policy Optimization) is a RL algorithm that eliminates the need for a separate critic/value model by using group-relative advantages. It generates multiple candidate outputs per prompt, scores them and normalizes rewards within the group to get advantages. It also uses ratio clipping (similar to PPO) to prevent the policy from drifting too far from the reference distribution. Instead of imitating expert reasoning traces (SFT), it lets the model discover its own strategies by generating multiple candidate solutions per problem, scoring them and reinforcing the better ones.
You can read more about it in the GRPO derivation blog post I wrote a few weeks back and in this blog post.
Building the Training Loop
I followed the same approach as I mentioned in the assignment whiere I wrote and tested the helper functions first and made sure each piece works in isolation. Finally, wired all the helper functions together into the full training loop.
The GRPO algorithm has two nested loops:
- Outer loop: sample a batch of prompts, generate G
rolloutsper prompt via vLLM, compute rewards, normalize advantages within each group - Inner loop: policy gradient updates over the rollout batch (using gradient accumulation to fit on the GPU)
Note, I have made sure to reuse the functions, data pipelines etc. from the SFT code wherever possible.
For the training data, I used the MATH dataset (problems only, no reasoning traces) sourced from this CS336 MATH dataset repo.
The core GRPO functions (group-normalized rewards, four loss variants, microbatch train step) live in utils/grpo.py and the main training script that wires the outer and inner loops together is train_grpo.py. You can find all the key files and details in the GRPO README.
A few important notes:
- I used the same vLLM colocate setup and workarounds as I did for SFT (see the SFT blog post for the debugging details). This allowed me to run the training loop and intermediate evaluations and rollout generations on a single GPU.
- All training configs are managed via OmegaConf structured configs and yaml files. This is especially useful for ablation studies where each experiment config is a minimal diff from the defaults, making it easy to see exactly what changed and importantly to reproduce any run.
- As usual, I added intermediate evaluations, model checkpointing at configurable intervals, wandb logging, other eval and timging metrics for better observability.
To keep costs manageable, all intermediate evaluations use a 1024 examples subset of the validation set rather than the full ~5K.
GPU Memory Optimization (Fitting on 24 GB)
I wrote the training code and tested it on my personal RTX 4090 with 24 GB of VRAM. With the default parameters suggested in the assignment, I immediately ran into OOM errors and had to do some memory optimizations to fit the training loop.
- Peak memory tracking: Not an optimization in itself but an essential step to keep track of the peak memory usage. I made sure to log the peak memory at important junctures in the training loop.
- Gradient checkpointing: The simplest one is to enable gradient checkpointing which recomputes activations during backward pass instead of storing them. You can trade up to ~30% memory savings for speed.
- vLLM sleep mode: This is quite a nice trick to offload vLLM KV cache and weights to CPU during the training phase (when vLLM is not generating). This frees GPU memory for the backward pass and prevents the vLLM cache from competing with training activations.
- 8-bit AdamW: I added an option to use bitsandbytes
AdamW8bitoptimizer instead of the defaultAdamWoptimizer. This reduces the optimizer state memory by almost half.
After all the above optimization tricks, I was able to successfully train with rollout_batch_size=256, group_size=8, gradient_accumulation_steps=256 (microbatch size = 1) on 24 GB.
You should be able to run most of the ablation studies on your local RTX 4090/3090 GPU with the default configs and optimization flags.
Scaling to Modal (H100s)
The local training script runs fine on a 24 GB GPU (e.g. RTX 4090) but there are two practical limitations that made me want to scale to Modal:
- Speed: Even with all memory optimizations, a single experiment on the 4090 takes a few hours. Some of the ablation studies and hyperparameter searches become impractical. It always helps to run the experiments on a larger GPU for faster iterations.
- Parallelism: I wanted to run a lot of ablation experiments. On a single local GPU that means running them one at a time which would take weeks. I needed a way to fire off multiple experiments in parallel and compare them side-by-side in wandb. At the same time, I am not spending my full time on this and I work on it whenever I get time. Thus, I did not want to deal with spinning up and shutting down GPU instances each time.
Modal lets you define GPU workloads purely in Python (no Docker/Kubernetes), with pay-per-second billing and containers that spin up in seconds. I could fire off multiple H100 runs in parallel and everything scales back to zero when done.
H100 Config Optimization
On the H100, I disabled the memory tricks that only exist to fit on 24 GB (gradient checkpointing, 8-bit AdamW) and used larger microbatches (4 instead of 1) for better tensor core utilization. I kept vLLM sleep mode on since it is still useful to free KV cache during training.
Timing comparison (20 GRPO steps, reinforce_with_baseline):
| Hardware | Config | Time |
|---|---|---|
| RTX 4090 (24 GB) | RTX 4090 defaults | ~28 min |
| H100 (80 GB) | RTX 4090 defaults (unchanged) | ~18 min |
| H100 (80 GB) | H100 optimized config | ~10 min |
Cost note: Running all the ablation studies discussed below including failed experiments and runs I terminated early, cost approximately $140 on Modal. I think that is well worth it for the understanding I gained.
Ablation Studies
I ran a series of ablation studies as per the assignment to understand what matters in GRPO training. Each ablation isolates one design choice while keeping everything else fixed.
You will notice the experiments vary in length: some run for 200 GRPO steps, some for 100/50 or some were terminated mid-way. This is intentional and done to keep the total cost manageable while still getting the information I needed.
Learning Rate Sweep
The learning rate is the most critical hyperparameter to get right first. It determines whether the policy updates are large enough to learn but not so large to cause the policy to collapse. Moreover, unlike supervised learning where a bad lr just causes loss divergence, in GRPO a high lr can cause the policy to collapse onto degenerate outputs before learning anything useful.
To find the right lr, I ran a log-spaced search from 1e-6 to 1e-4 for 100 steps each on H100.
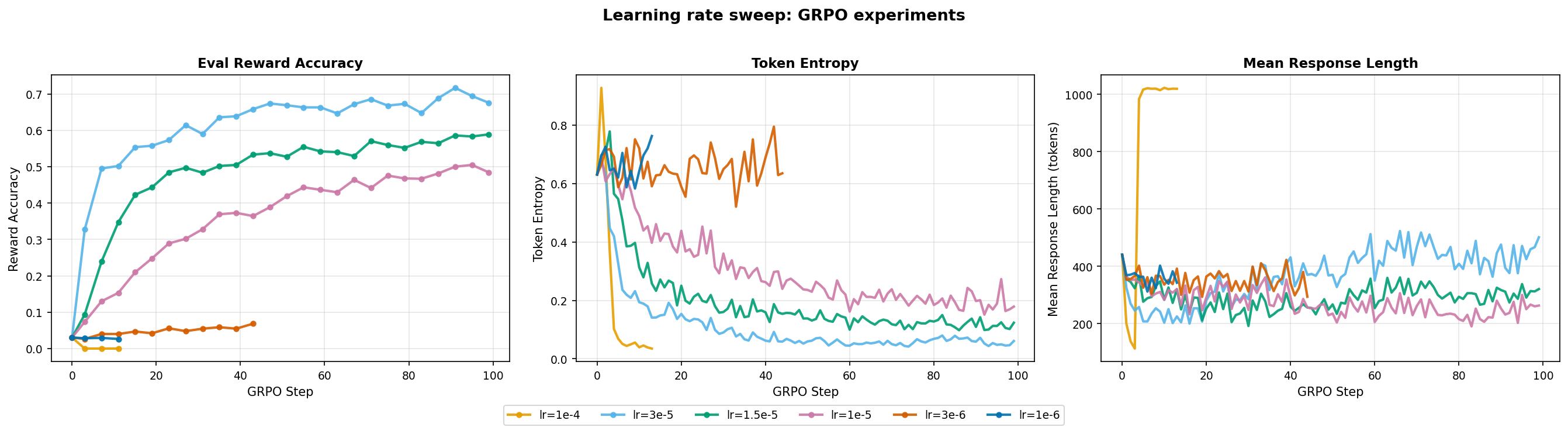
1e-6and3e-6barely move the eval reward accuracy. The gradient signal is too small to update the policy meaningfully.1e-4shows policy collapse with mean response length spikes and token entropy dropping to near zero.1e-5to3e-5: reward rises steadily, response length stabilizes and token entropy drops smoothly.
Winner:
lr=3e-5as it gives the most stable training and highest reward accuracy. I used this for all future runs.
Baseline Ablation
The vanilla REINFORCE gradient has notoriously high variance. A common technique is to subtract a baseline (the group mean reward) from the advantage which reduces variance without introducing bias. Here I tested whether that variance reduction actually matters in practice.
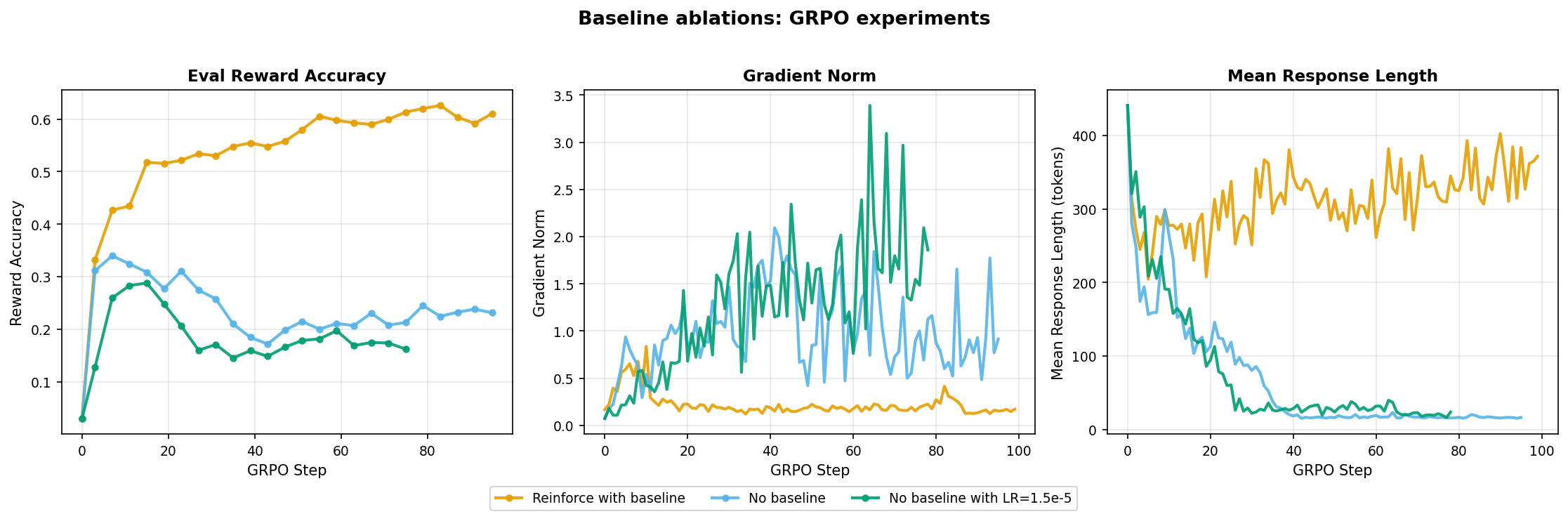
reinforce_with_baseline: evaluation reward accuracy steadily climbs to ~0.61 with stable gradient norm and consistent mean response length around 300-350 tokens.- Both
no_baselineruns peak early then decline. Their gradient norm is way high and seems to keep increasing, and both suffer rapid response length collapse after some steps.
Subtracting the group mean reward from the advantage reduces variance and prevents response length collapse.
reinforce_with_baselineis the clear choice.
Length Normalization
When aggregating per-token losses over the sequence dimension, the choice of normalization affects how much gradient signal each individual token receives. As noted in the assignment, it is not necessary or even correct to always average losses by sequence length. I tested three modes:
mean: divide by number of response tokens per sequence. In this case, short correct answers get disproportionately large per-token gradients.constant: divide by a fixed constant (max_gen_len=1024). Every token gets the same gradient magnitude regardless of sequence length (used in DeepSeek).microbatch: normalize by the longest response in the current microbatch. This is a middle ground betweenmeanandconstant.
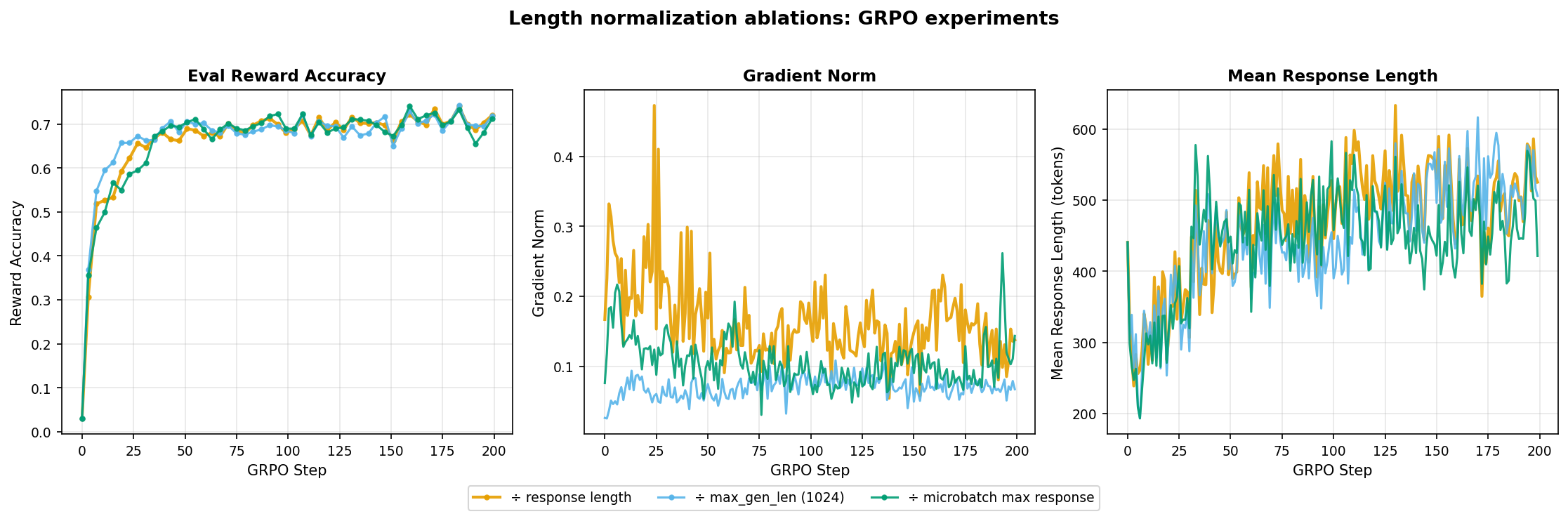
- All three modes converge to similar final reward accuracy and mean response length.
- The main difference is in gradient norm.
constantproduces consistently lower norms in comparison tomicrobatchandmean. This is expected sinceconstantdivides everything by 1024 (max generation length), which is 2-2.5x larger than typical response length.
Length normalization mode has minimal impact on final reward for math reasoning with binary reward. The primary observable difference is in gradient scale and not learning dynamics. I kept
meanas the default.
Standard Deviation Normalization
The standard GRPO advantage computation divides by the group standard deviation: advantage_i = (reward_i - mean(group)) / (std(group) + eps). But Dr. GRPO argued that this can introduce unwanted biases where groups with low variance (too easy or too hard questions where all rollouts get the same reward) produce near-zero std deviation, inflating their advantages disproportionately. They proposed removing the division entirely. This ablation tests whether removing that division actually helps.
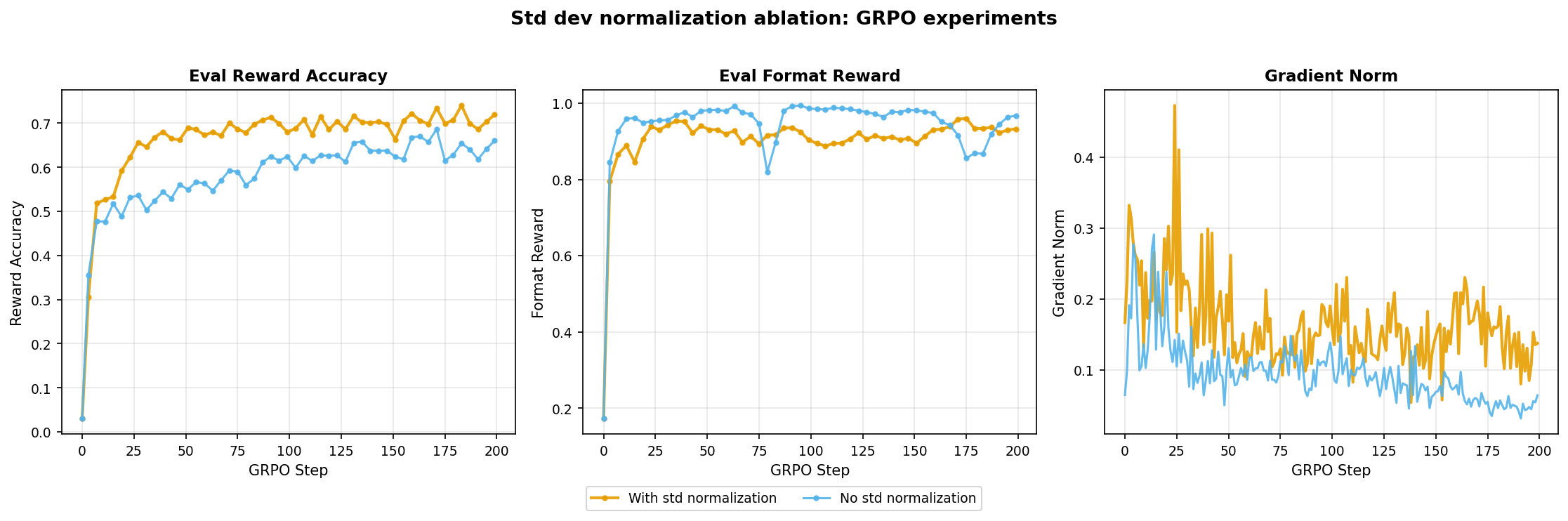
- With std normalization: reaches higher final reward accuracy (~0.72).
- Without: plateaus at ~0.65, but gradient norms are lower and more stable.
Removing std dev normalization does improve gradient stability and this confirms the observation that dividing by group std dev. amplifies gradients for low-variance groups. However, the improved stability does not translate to better performance here. The ~0.07 reward gap is substantial enough to justify the slightly noisier gradients.
Winner: keep std normalization as the reward benefit outweighs the noisier gradients.
Off-Policy Sweep
On-policy training is clean but we are generating a full batch of rollouts just to take a single gradient step. I wanted to test how far I could push off-policy reuse (multiple gradient steps per rollout batch) before the policy drifts too far and training destabilizes.
Broad sweep (50 steps)
First, I ran a broad sweep over 6 configs varying epochs_per_rollout_batch and train_batch_size ranging from on-policy (1 optimizer step per GRPO step) to aggressive off-policy (16 optimizer steps per GRPO step). All runs use grpo_clip loss, lr=3e-5.
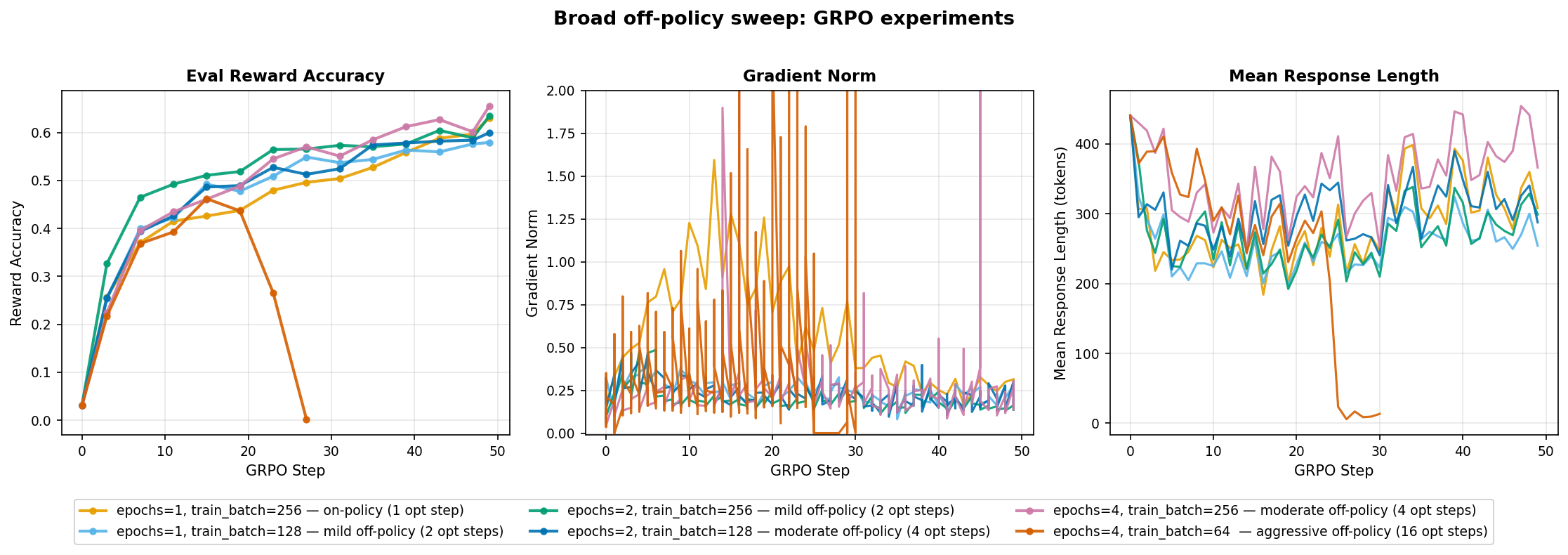
- Most configs converge to ~0.55-0.65. The clear outlier is
e4_tb64_ga16(16 opt steps/GRPO). It collapses mid-way with gradient norm spikes and response length collapsing to ~100 tokens. This is a classic failure mode where the policy drifts too far from the rollout distribution and the model learns to produce minimal outputs. - Mild off-policy (2 opt steps/GRPO) works as well as on-policy.
Aggressive off-policy reuse (16 opt steps/GRPO) causes policy collapse. Mild off-policy (2 opt steps) looks comparable to on-policy in this short sweep.
Full sweep (200 steps)
I then selected the three most promising configs (on-policy and two mild off-policy) for full 200 step training.
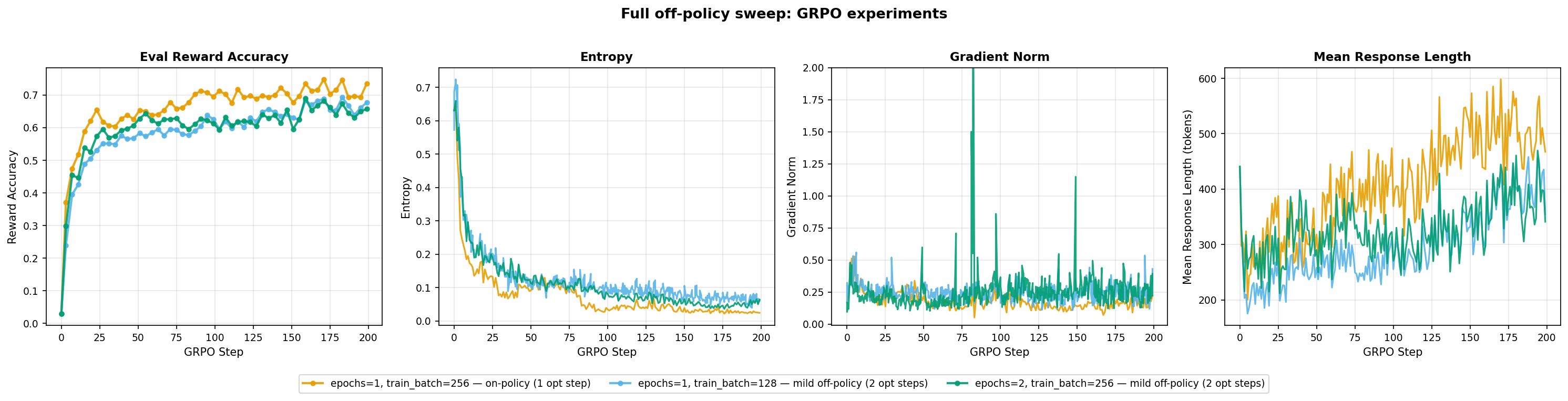
- On-policy (
e1_tb256_ga64) is consistently the best. It converges fastest and maintains highest reward accuracy (~0.65-0.75). The two mild off-policy configs track slightly behind it. e2_tb256_ga64(2 epochs) shows higher gradient norm variance with spikes but doesn’t destabilize.
On-policy training works better in this case. Reusing rollouts does not help and the extra compute per GRPO step is not justified by the performance gain.
Prompt Template Ablation
Here, I compared the r1_zero prompt (structured <think>...</think> and <answer>...</answer> blocks) against question-only (just {question}), each with a matching reward function.
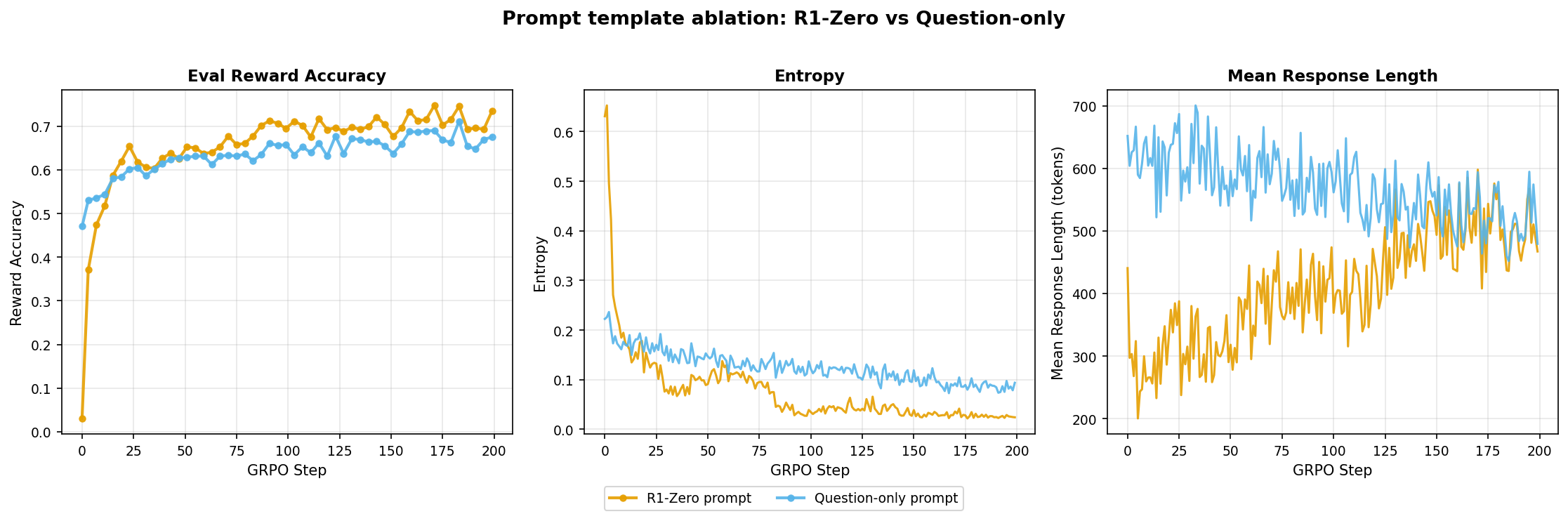
- Question-only starts with much higher accuracy because Qwen2.5-Math-1.5B seems to be pre-trained on math data with
\boxed{}formatting. It already solves nearly half the problems out of the box. In comparison, r1-zero starts near zero (unfamiliar format) but catches up quickly once the model learns the structured format. Finally, r1-zero consistently performs better than question-only by the end. - r1-zero settles at much lower entropy in comparison to question-only. This is expected since the r1-zero prompt is more structured and constrains the output space
Winner: R1-zero structured prompt as it provides a dedicated reasoning scratchpad for the model to reason before committing to an answer. Without this, reasoning is interleaved with the answer in less predictable ways.
SFT Checkpoint Initialization
This was not part of the assignment but I thought it would be interesting to see how starting from an SFT checkpoint affects performance. We already have an SFT model that gets ~53% accuracy, can GRPO push it even higher?
I ran five runs: base model (no SFT), three SFT checkpoints (early/mid/final) and final with lower lr.
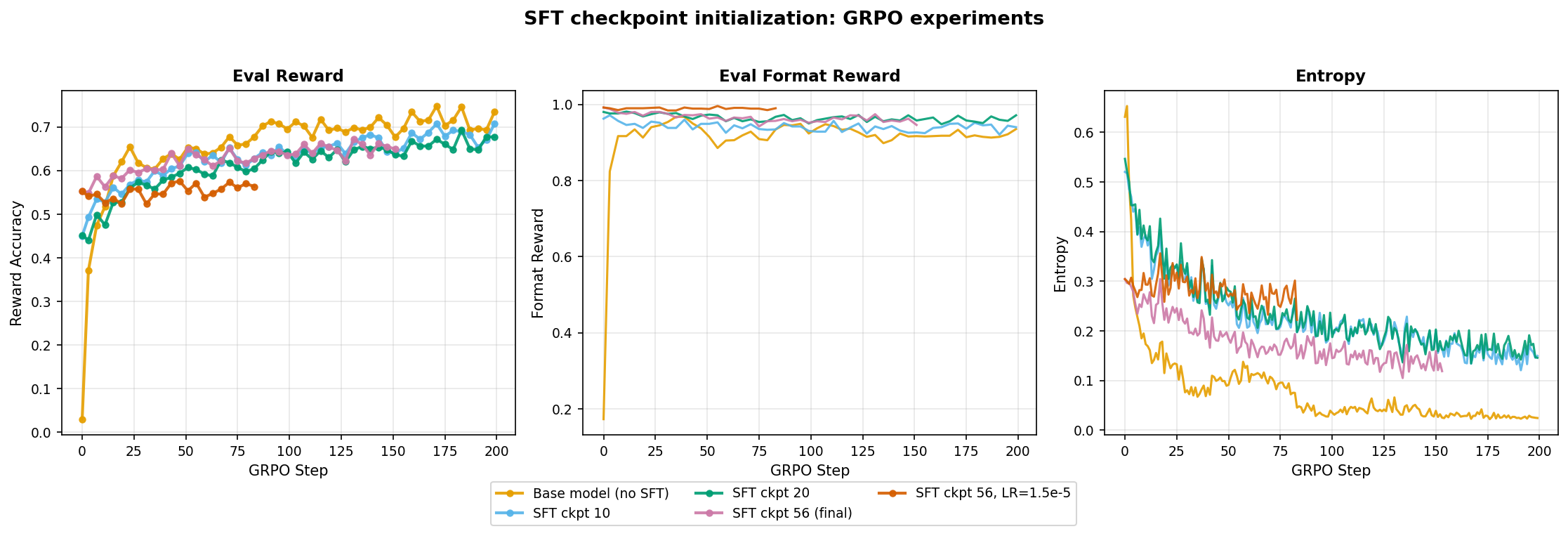
- The base model (no SFT) still performs better than the SFT runs. As we use more and more SFT trained checkpoints, the GRPO ceiling plateaus at lower and lower accuracy. Similarly, we see higher entropy in the SFT runs in comparison to the base model.
- This indicates that the SFT checkpoints are not helping GRPO training and are actually hurting it. SFT narrows the policy distribution early on, limiting the exploration that RL needs to discover better strategies. The more SFT training the checkpoint has seen, the narrower the distribution and the lower the GRPO ceiling.
SFT initialization hurts in this case, the pre-narrowed distribution limits exploration before RL even starts.
Summary and Key Takeaways
Best configuration:
- on-policy (
epochs_per_rollout_batch=1) - lr=
3e-5 - loss_type=
grpo_clip - use_std_normalization=
True r1_zerostructured prompt- base model (no SFT initialization)
Best performance: ~0.75 on MATH validation (up from ~3% base model accuracy).
Key lessons:
- Eval reward accuracy is the north star metric. It directly measures what we care about. Especially in the case of reinforcement learning with verifiable rewards.
- However, gradient norm and mean_response_length are the two other important metrics to watch. They are the early warning signals for instability and reward collapse.
- Binary math reward is robust to some design choices (length normalization) but sensitive to others (baseline subtraction, learning rate).
- On-policy training wins in this case, reusing rollouts introduces policy drift that is not worth the compute savings.
- The R1-zero structured prompt matters. A dedicated reasoning scratchpad produces sharper final policies and higher accuracy.
- SFT initialization does not help in this case.
Ideally, I should now try to push the accuracy further by training for longer, using curriculum strategies or modifying the GRPO loss itself. But that’s for another time! I think it is enough learning and compute expense for now.
Resources
Papers and Blog Posts
- Deriving the GRPO Loss: My blog post deriving the GRPO loss function
- CS336 Assignment 5: Stanford CS336 alignment assignment I followed as a reference
- Building SFT from Ground Up: My previous SFT experiments blog post
- Expert Iteration for Math Reasoning: My Expert Iteration experiments blog post
Code and Artifacts
- Code: building-from-scratch/grpo
- Configs: grpo/configs
- Trained Checkpoints: garg-aayush/cs336-grpo-exps
- Datasets: CS336 MATH dataset
- Training Logs: wandb.ai/garg-aayush/grpo