A couple of months back, I enrolled in AI Evals for Engineers and PMs, a course by Hamel and Shreya. The live cohort for ot ran from July to mid-August, but due to work commitments I couldn’t follow along in real time.
I have now started following it as a self-paced course and plans to write a blog for each lesson as I progress. This will be my way to capture what I learn and to reflect on the material. In this first blog 🤞, I’ll walk through my key takeaways from introductory Lecture 1.
Key Takeaways
1. Evaluation isn’t Optional but Fundamental
Anyone who has built or worked with LLM pipelines knows that their outputs are open-ended, subjective, and unstructured (unless you enforce it). If you rely on ad-hoc checks which I have been guilty of, it often leads to knee-jerk fixes. Moreover, it completely miss the long-term need of continuous tracking which is essential for improving your pipeline reliability and usefulness. This is why Evaluation—the systematic measurement of an LLM pipeline quality—is critical!
2. The Three Gulfs
The below image beautifully captures and categorizes the challenges associated with any LLM application:
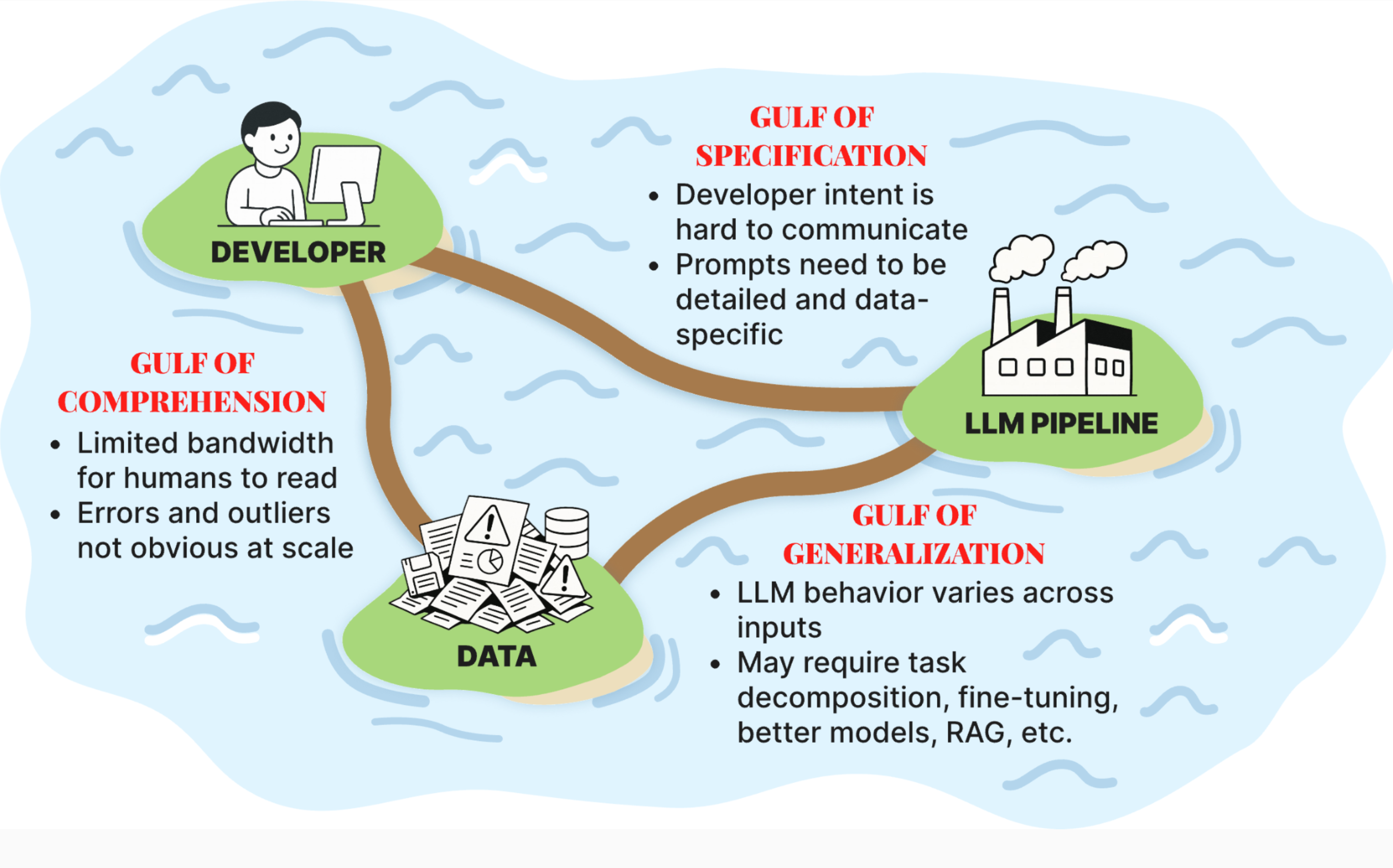
-
Gulf of Comprehension: This is a result of limited understanding of the input data (user queries) and the pipeline’s outputs (behavior). Bridging it requires examining examples to identify common failure modes. This brings it own challenge: “How to manually review every input or output to identify failure modes?”
-
Gulf of Specification: It refers to the difficulty of translating a user’s high-level intent into unambiguous precise instructions for the LLM. Bridging it requires writing detailed prompts that captures “true intent” which in itself is challenging due to ambiguous nature of natural language.
-
Gulf of Generalizaton: This is due to LLMs unexpected and inconsistent behavior on new or unusual (out of distribution) inputs. Bridging it requires a good understanding of your LLM model capabilities. This leads to the question: “How to improve LLM model?”
3. Analyze → Measure → Improve Lifecycle
Hamel and Shreya introduced a structured way to bridge the above gulfs: Analyze → Measure → Improve lifecycle.
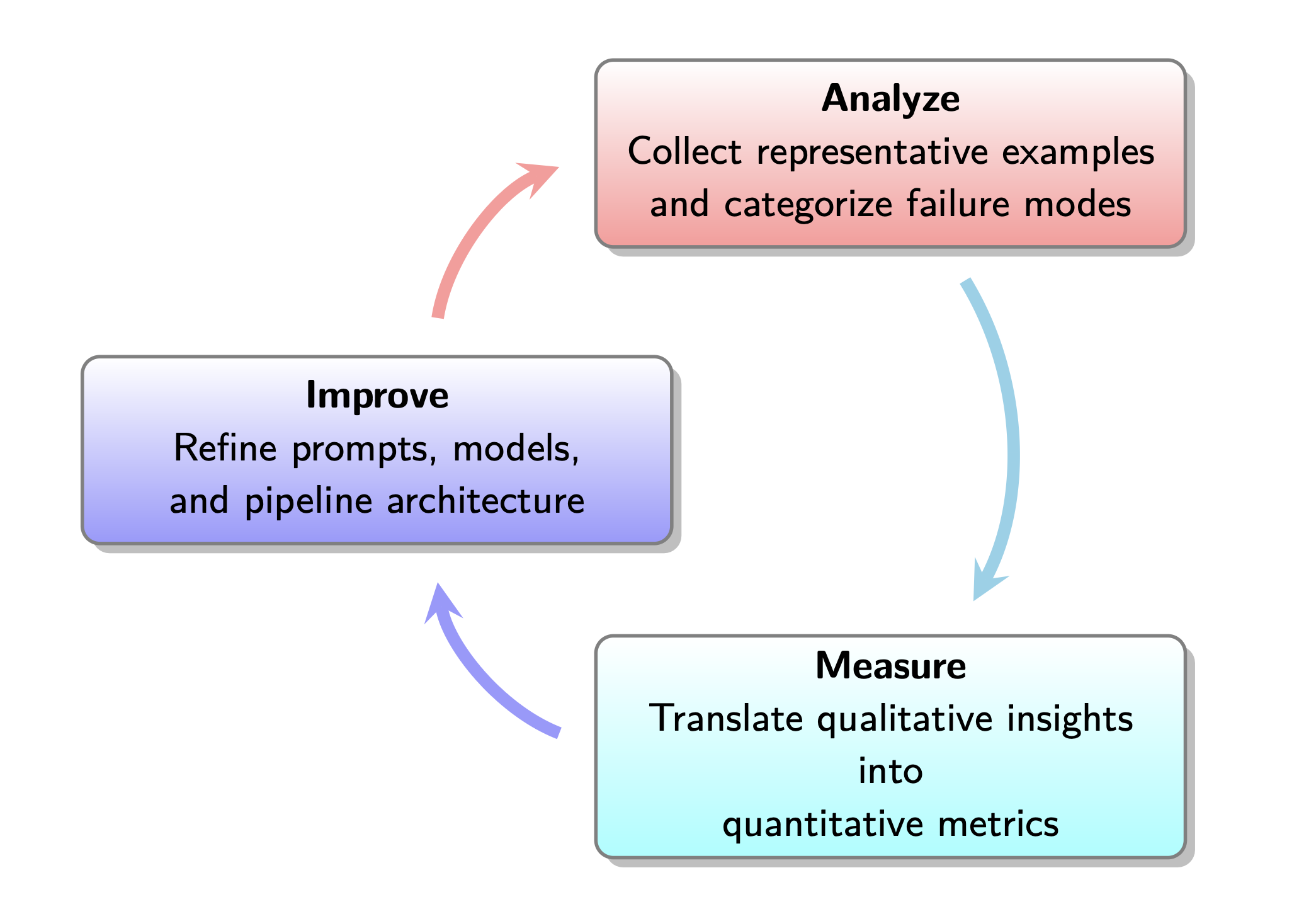
However, the most important takeaways for me was not what each phase means but the pitfalls that often derail them:
| Phase | Pitfalls | Notes |
|---|---|---|
| Analyze | Outsourcing annotation; looking at too few examples and forming shaky hypotheses | This is where you learn the most. Spend ~75–80% of your time here—good analysis sets up everything else. |
| Measure | Misaligned or poorly designed LLM judges; “overfitting” by testing judges on the same examples used in the judge prompt | In this phase, you need the rigor of data science. NEVER leak test data into judge prompts. |
| Improve | Prematurely jumping to fixes; defaulting to the most complex solution first (fine-tuning, bigger models) | Start simple. Prompt tweaks and improvements often go a long way before heavier changes are needed. |
4. LLMs are Imperfect—Prompt Iteratively
When we write prompts it’s easy to ignore that LLMs are non-deterministic, prompt-sensitive and can confidently hallucinate. Thus, always remember: “LLMs are powerful but imperfect components. Leverage strengths, anticipate weaknesses.”

Effective prompting starts with you. You should not delegate the prompting to an LLM or you will miss important failure modes. Instead, write your own draft prompt and if needed, use an LLM only to polish clarity.
From there on, treat prompting as an iterative process where the first draft is a starting point which you refine based on observed outputs.
5. Reference-based vs Reference-free Metrics
The evaluation metrics broadly fall into two categories: reference-free and reference-based. Both of them are useful but in different contexts.
| Reference-Free | Reference-Based | |
|---|---|---|
| What it means | Evaluates properties of the output itself (no golden answer required) | Compares output against a golden reference or ground truth |
| When to use | Creative or open-ended tasks, formatting/structure checks, validity tests | Tasks with clearly defined correct answers (e.g., factual QA, deterministic outputs) |
| Examples | - Does the output follow the JSON format? - Does generated code/SQL run without errors? |
- Exact match against a gold SQL query - ROUGE/BLEU score for text generation |